
你是否也遇到过这些烦恼?
- 图片/PDF里的文字无法复制? —— 想提取截图、扫描件或电子书中的文字,却只能手动打字,效率极低!
- 批量处理图片太麻烦? —— 几十张图片要识别,一张一张操作,费时费力!
- 水印干扰识别结果? —— 截图或PDF上有LOGO、页眉页脚,OCR后混入无用文字,还得手动删除!
- 二维码信息难获取? —— 遇到二维码想快速查看内容,却找不到好用的扫码工具!
📖 一、软件界面介绍
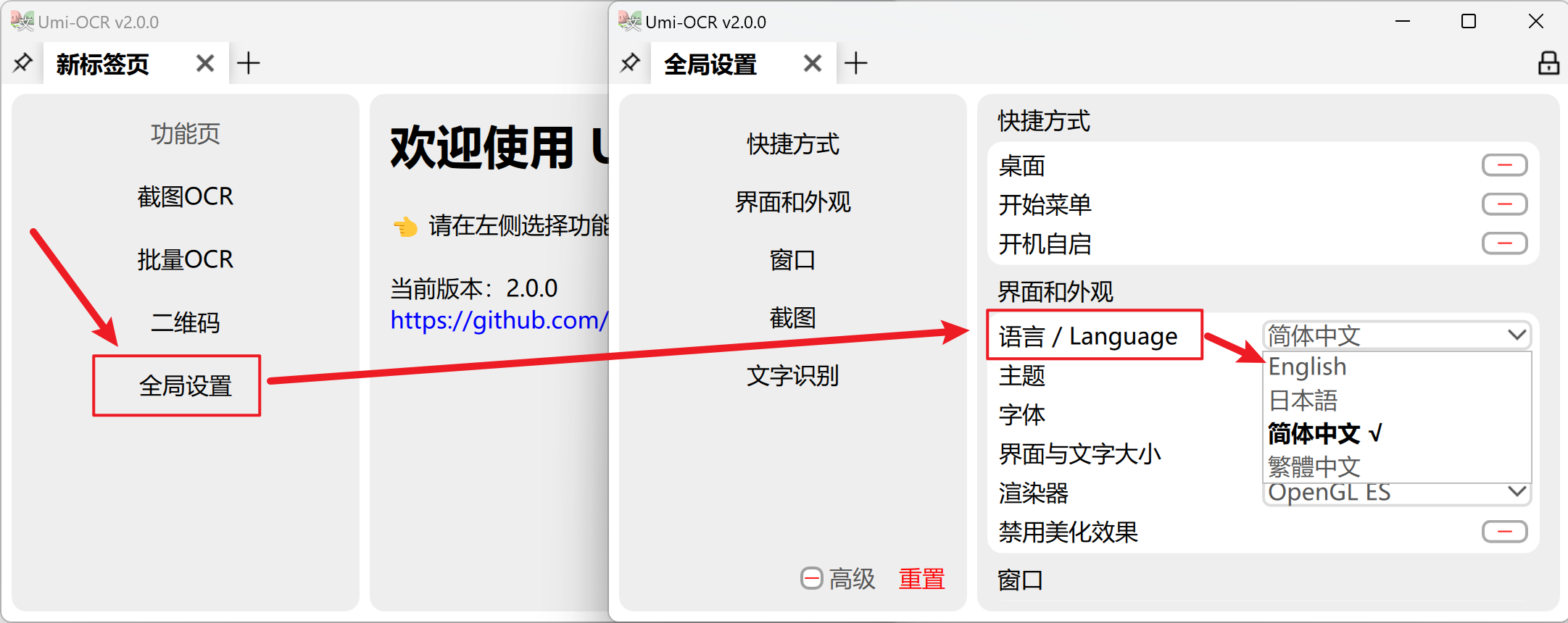
- 多语言支持:打开软件时自动匹配系统语言,也可手动切换(顶部菜单栏→全局设置→语言)。 ![语言设置示例图] (配图:语言选择下拉菜单截图)
- 标签页功能:
- 像浏览器一样,可同时打开多个功能页(如截图OCR、批量OCR等)。
- 小技巧:点击标签栏右上角的📌可锁定标签页,防止误关。
🖼️ 二、截图OCR(快速识别图片文字)
使用步骤:
- 打开“截图OCR”标签页,按默认快捷键
Ctrl+Shift+A(可修改)唤起截图。 - 鼠标框选需要识别的区域,松开后自动识别。 ![截图OCR操作动图] (配图:截图→识别→结果展示流程)
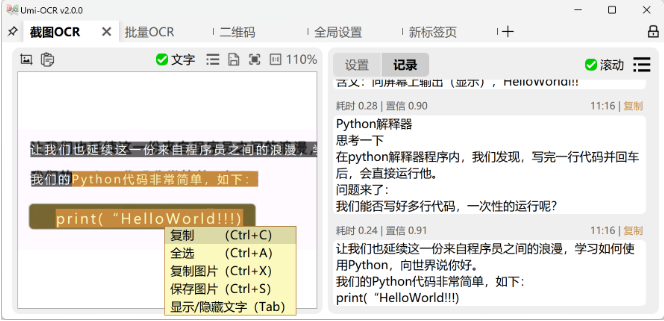
功能亮点:
- 左栏:直接划选文字复制。
- 右栏:可编辑识别结果,支持多选复制。
- 公式识别:勾选后能识别数学公式(需插件支持)。
📜 三、文本后处理(排版优化)
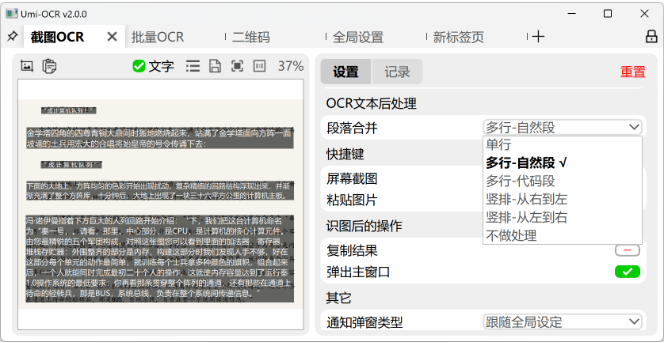
识别后的文字排版乱?试试这些预设方案:
- 推荐方案:
多栏-按自然段换行(自动整理多栏文本,如杂志页面)。 - 其他选项:
单栏-保留缩进:适合代码截图。不做处理:保留原始识别结果。 ![排版对比示例图] (配图:处理前后文本对比)
📂 四、批量OCR(处理大量图片)
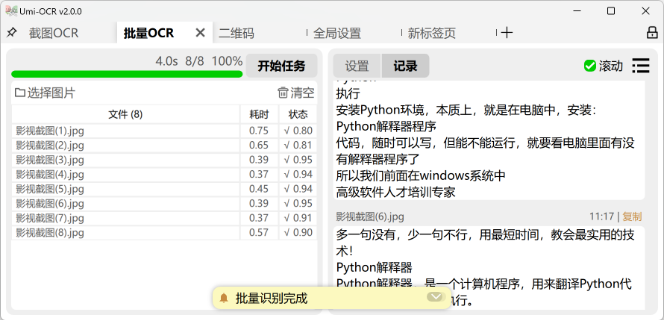
支持格式:JPG/PNG/PDF等常见图片格式。 操作流程:
- 拖入图片或点击导入。
- 选择输出格式(TXT/Excel等)。
- 点击“开始任务”。
高级功能:
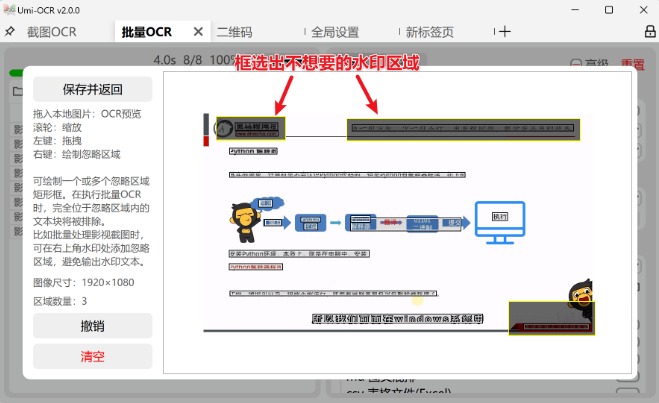
- 忽略区域:排除水印干扰(右键画框标记水印位置)。 ![忽略区域编辑示意图] (配图:红色框选水印区域)
- 自动关机:适合长时间批量任务。
📄 五、文档识别(PDF/电子书)
- 扫描件OCR:将图片PDF转为可搜索文字。
- 输出格式:支持生成双层PDF(保留原始排版+可选中文字)。
🔍 六、二维码工具
- 扫码:截图/拖入图片即可读取二维码。
- 生成码:输入文本→选择类型(如微信二维码)→生成并保存。 ![二维码生成界面] (配图:生成界面+常见码类型示例)
⚙️ 七、全局设置(个性化调整)
- 主题切换:亮色/暗色模式。
- 字体大小:调整界面文字。
- 硬件加速:若界面卡顿,尝试关闭此选项。
- 开机自启:一键设置更方便。
更新说明
新增功能
- 日志机制:在命令行中启动 Umi-OCR,即可查看实时日志。默认情况下,指定级别以上(默认为ERROR)的日志将被保存到
Umi-OCR/UmiOCR-data/logs目录中。你可以在全局设置标签页中更改保存级别,以便更好地监控软件运行状态。 - 双栏模式切换:大部分标签页现在支持手动切换左右/上下双栏模式,让你可以根据自己的使用习惯调整界面布局(#789)。
- Esc键隐藏主窗口:按下Esc键即可快速隐藏主窗口,方便你在使用其他软件时快速切换,提高工作效率(#652)。
- 二维码生成自动刷新:调整二维码生成相关参数后,二维码将自动刷新,无需手动操作,让二维码生成更加便捷(#690)。
- 命令行指令 –reload:新增命令行指令
--reload,用于重新加载配置文件,方便你在修改配置后快速应用新设置。👉文档
修复问题
- 文档识别页面旋转问题:修复了文档识别提取PDF自带文本内容时,未考虑页面旋转影响的问题(#785)。
- 单层PDF生成问题:修复了文档识别生成单层PDF时,未写入原PDF自带文本内容的问题。
- OCR结果展示问题:修复了OCR结果展示列表的一些显示Bug和鼠标划选Bug,让结果展示更加准确。
- 标签页顺序保存问题:修复了调整标签页顺序或删除标签页后,未及时保存顺序信息的问题。
- HTTP接口参数错误:修复了HTTP接口
/api/doc/download参数ignore_blank的错误。 - Linux版本截图问题:修复了Linux版本截图时,系统任务栏推移顶层窗口导致截图位置偏移的问题(#778)。
- Linux版本窗口位置问题:修复了Linux版本截图后,主窗口位置与操作前不一致的问题。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。E-mail:ziyuanhe6@qq.com
